JDK8 特性(二)
ZhuHJay 2022/5/24 JDK8
# 1 Stream流
# 1.1 集合处理数据的弊端
案例引入:
- 首先筛选所有姓张的人;
- 然后筛选名字有三个字的人;
- 最后进行对结果进行打印输出。
传统实现
public class StreamDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Collections.addAll(list, "张三丰", "周芷若", "张无忌", "赵敏", "张强");
// 1. 首先筛选所有姓张的人;
List<String> zhangList = new ArrayList<>();
for (String name : list) {
if(name.contains("张")){
zhangList.add(name);
}
}
// 2. 然后筛选名字有三个字的人;
List<String> threeList = new ArrayList<>();
for (String name : zhangList) {
if(name.length() == 3){
threeList.add(name);
}
}
// 3. 最后进行对结果进行打印输出。
for (String name : threeList) {
System.out.println(name);
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
- Stream流式实现
public class StreamDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Collections.addAll(list, "张三丰", "周芷若", "张无忌", "赵敏", "张强");
// 1. 首先筛选所有姓张的人; 2. 然后筛选名字有三个字的人; 3. 最后进行对结果进行打印输出
list.stream()
.filter(str -> str.contains("张"))
.filter(str -> str.length() == 3)
.forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
# 1.2 Stream流式思想概述
注意:Stream和IO流(InputStream/OutputStream)没有任何关系,请暂时忘记对传统IO流的固有印象!
Stream流式思想类似于工厂车间的“生产流水线”,Stream流不是一种数据结构,不保存数据,而是对数据进行加工处理。Stream可以看作是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商品。
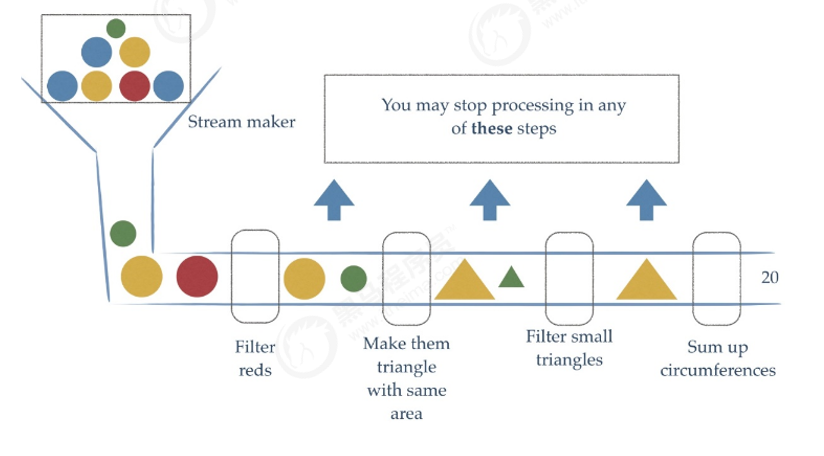
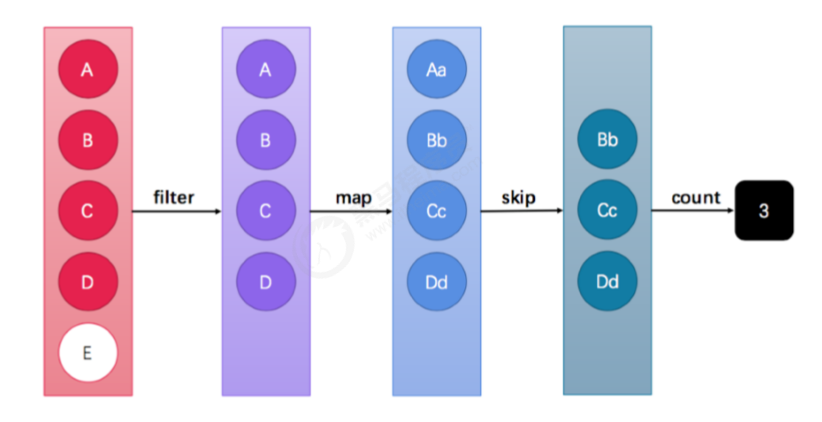
Stream API能让我们快速完成许多复杂的操作,如筛选、切片、映射、查找、去除重复,统计,匹配和归约。
# 1.3 获取Stream流的两种方式
- 方式一
- Collection集合接口中有默认方法
default Stream<E> stream(){...} - 也就是说实现该接口的集合类都可以直接调用stream()方法获取流对象
- Collection集合接口中有默认方法
- 方式二
- Stream中的静态方法
static<T> Stream<T> of(T t){...} - 可以调用该方法获取流对象
- Stream中的静态方法
# 1.4 了解Stream流的常用方法和注意事项
- Stream常用方法
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
终结方法:返回值类型不再是 Stream 类型的方法,不再支持链式调用。
非终结方法:返回值类型仍然是 Stream 类型的方法,支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
Stream注意事项
- Stream只能操作一次
- Stream方法返回的是新的流
- Stream不调用终结方法,中间的操作不会执行
# forEach
- forEach用来遍历流中的数据 -> 终结方法
void forEach(Consumer<? super T> action);
1
- 该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void forEach(){
list.stream().forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# count
- count方法来统计其中的元素个数 -> 终结方法
long count();
1
- 该方法返回一个long值代表元素个数。基本使用
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void count(){
System.out.println(list.stream().count());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# filter
- filter用于过滤数据,返回符合过滤条件的数据 -> 非终结方法
Stream<T> filter(Predicate<? super T> predicate);
1
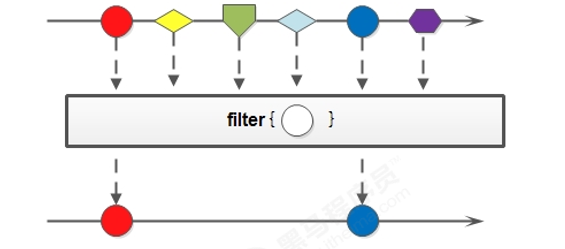
该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void filter(){
// 计算名字长度为3的人数
System.out.println(list.stream().filter(name -> name.length() == 3).count());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# limit
- limit 方法可以对流进行截取,只取用前n个 -> 非终结方法
Stream<T> limit(long maxSize);
1
- 参数是一个long型,如果集合当前长度大于参数则进行截取。否则不进行操作
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void limit(){
list.stream().limit(3).forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# skip
- 如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流 -> 非终结方法
Stream<T> skip(long n);
1
- 如果流的当前长度大于n,则跳过前n个; 否则将会得到一个长度为0的空流。
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void skip(){
list.stream().skip(3).forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# map
- 如果需要将流中的元素映射到另一个流中,可以使用 map 方法 -> 非终结方法
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
1
- 该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void map(){
list.stream()
// 类型增强
.map(name -> "name: " + name)
.forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# sorted
- 如果需要将数据排序,可以使用 sorted 方法。 -> 非终结方法
Stream<T> sorted(); // 根据元素的自然顺序排序
Stream<T> sorted(Comparator<? super T> comparator); // 自定义比较器排序
1
2
2
- 该方法可以有两种不同地排序实现
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void sorted(){
list.stream()
// 默认自然序
.sorted()
// 执行比较器进行排序
.sorted(((o1, o2) -> o1.length() - o2.length()))
.forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# distinct
- 如果需要去除重复数据,可以使用 distinct 方法 -> 非终结方法
- 自定义类型是根据对象的 hashCode 和 equals 来去除重复元素的
Stream<T> distinct();
1
- 基本使用
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void distinct(){
list.add("迪丽热巴");
list.add("张无忌");
list.stream()
.distinct()
.forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# match
- 如果需要判断数据是否匹配指定的条件,可以使用 Match 相关方法 -> 终结方法
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
1
2
3
2
3
- 基本使用
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void match(){
// allMatch 所有元素都需要满足
System.out.println(list.stream()
.allMatch(name -> name.contains("张")));
// anyMatch 如果有元素满足即可
System.out.println(list.stream()
.anyMatch(name -> name.contains("张")));
// noneMatch 所有元素都不满足
System.out.println(list.stream()
.noneMatch(name -> name.contains("男")));
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# find
- 如果需要找到某些数据,可以使用 find 相关方法 -> 终结方法
Optional<T> findFirst();
Optional<T> findAny();
1
2
2
- 基本使用
public class StreamTest {
private List<String> list;
@Before
public void before(){
list = new ArrayList<>();
Collections.addAll(list, "迪丽热巴", "张三丰", "周芷若", "张无忌", "赵敏", "张强");
}
@Test
public void find(){
// 都是获取第一个元素
Optional<String> optional = list.stream().findAny();
Optional<String> optional1 = list.stream().findFirst();
System.out.println(optional.get());
System.out.println(optional1.get());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# max && min
- 如果需要获取最大和最小值,可以使用 max 和 min 方法 -> 终结方法
Optional<T> max(Comparator<? super T> comparator);
Optional<T> min(Comparator<? super T> comparator);
1
2
2
- 基本使用
public class StreamTest {
@Test
public void min_max(){
// 传入一个比较器, 排序完后获取最后一个
Optional<Integer> max = Stream.of(4, 2, 7, 1).max((o1, o2) -> o1 - o2);
System.out.println(max.get());
// 传入一个比较器, 排序完后获取第一个
Optional<Integer> min = Stream.of(4, 2, 7, 1).min((o1, o2) -> o1 - o2);
System.out.println(min.get());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
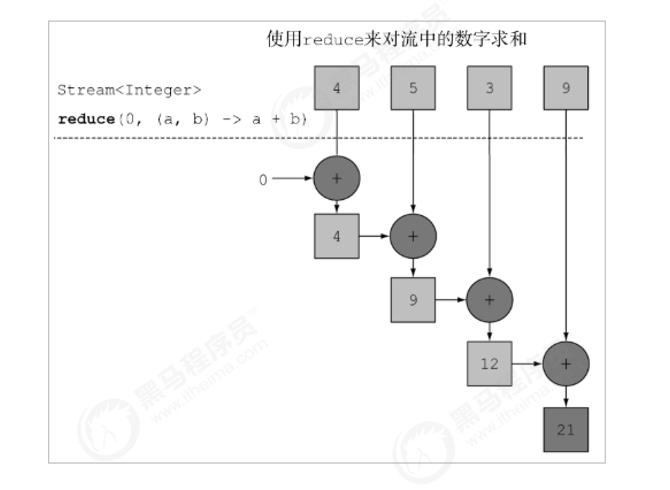
# reduce
- 如果需要将所有数据归纳得到一个数据,可以使用 reduce 方法 -> 终结方法
T reduce(T identity, BinaryOperator<T> accumulator);
1
- 基本使用
public class StreamTest {
@Test
public void reduce(){
Integer reduce = Stream.of(4, 5, 3, 9)
// T identity: 默认值
// BinaryOperator<T> accumulator: 对数据的处理方式
// 获取最大值, 初始值为0
.reduce(0, Integer::max);
System.out.println(reduce);
reduce = Stream.of(4, 5, 3, 9)
// T identity: 默认值
// BinaryOperator<T> accumulator: 对数据的处理方式
// 获取加和结果, 初始值为0
.reduce(0, Integer::sum);
System.out.println(reduce);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# map && reduce结合
- 使用案例
public class StreamTest {
@Test
public void reduceAndMap(){
// 获取最大年龄
Optional<Integer> maxAge = Stream.of(
new Person("张三", 18),
new Person("李四", 20),
new Person("王五", 17),
new Person("小红", 19),
new Person("小明", 18))
.map(Person::getAge)
.reduce(Integer::max);
System.out.println(maxAge.get());
// 获取年龄总和
Optional<Integer> totalAge = Stream.of(
new Person("张三", 18),
new Person("李四", 22),
new Person("王五", 17),
new Person("小红", 19),
new Person("小明", 21))
.map(Person::getAge)
.reduce(Integer::sum);
System.out.println(totalAge.get());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# mapToInt
- 如果需要将Stream中的Integer类型数据转成int类型,可以使用 mapToInt 方法 -> 终结方法
IntStream mapToInt(ToIntFunction<? super T> mapper);
1
该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流
public class StreamTest {
@Test
public void mapToInt(){
// Integer占用的内存比int多, 在Stream流中会自动拆箱装箱
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
// 将Integer类型转换为int类型, 可以节省空间
IntStream intStream = stream
.mapToInt(Integer::intValue);
}
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# concat
- 如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat -> 终结方法
- 这是一个静态方法,与
java.lang.String当中的 concat 方法是不同的
- 这是一个静态方法,与
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b){...}
1
- 基本使用
public class StreamTest {
@Test
public void concat(){
Stream<String> streamA = Stream.of("张三");
Stream<String> streamB = Stream.of("李四");
// 将以上流合并, 合并的流就不能够继续操作了
Stream.concat(streamA, streamB).forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 1.5 Stream综合案例
- 现在有两个 ArrayList 集合存储队伍当中的多个成员姓名,要求使用Stream实现若干操作步骤:
- 第一个队伍只要名字为3个字的成员姓名;
- 第一个队伍筛选之后只要前3个人;
- 第二个队伍只要姓张的成员姓名;
- 第二个队伍筛选之后不要前2个人;
- 将两个队伍合并为一个队伍;
- 根据姓名创建 Person 对象;
- 打印整个队伍的Person对象信息。
public class StreamCaseDemo {
public static void main(String[] args) {
List<String> one = new ArrayList<>();
List<String> two = new ArrayList<>();
Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子", "洪七公");
Collections.addAll(two, "古力娜扎", "张无忌", "张三丰", "赵丽颖", "张二狗", "张天爱", "张三");
Stream<String> streamOne = one.stream()
// 1. 第一个队伍只要名字为3个字的成员姓名
.filter(name -> name.length() == 3)
// 2. 第一个队伍筛选之后只要前3个人
.limit(3);
Stream<String> streamTwo = two.stream()
// 3. 第二个队伍只要姓张的成员姓名
.filter(name -> name.startsWith("张"))
// 4. 第二个队伍筛选之后不要前2个人
.skip(2);
// 5. 将两个队伍合并为一个队伍
Stream<String> stream = Stream.concat(streamOne, streamTwo);
// 6. 根据姓名创建 Person 对象
stream.map(Person::new)
// 7. 打印整个队伍的Person对象信息
.forEach(System.out::println);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 1.6 收集Stream流中的结果
- 对流操作完成之后,如果需要将流的结果保存到数组或集合中,可以收集流中的数据
# 收集结果到集合中
- Stream流提供 collect 方法,其参数需要一个
java.util.stream.Collector<T,A, R>接口对象来指定收集到哪种集合中。java.util.stream.Collectors类提供一些方法,可以作为Collector`接口的实例:public static <T> Collector<T, ?, List<T>> toList(): 转换为 List 集合public static <T> Collector<T, ?, Set<T>> toSet(): 转换为 Set 集合public static <T, C extends Collection<T>> Collector<T, ?, C> toCollection(Supplier<C> collectionFactory): 收集到指定的集合中
# 收集结果到数组中
- Stream提供 toArray 方法来将结果放到一个数组中
Object[] toArray(); // 返回Object数组
<A> A[] toArray(IntFunction<A[]> generator); // 返回指定数组
1
2
2
# 对流中数据进行聚合计算
- 当我们使用Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作。比如获取最大值,获取最小值,求总和,平均值,统计数量。
public class StreamCollectTest {
@Test
public void aggregation(){
List<Person> personList = Stream.of(
new Person("张三", 18),
new Person("李四", 22),
new Person("王五", 17),
new Person("小红", 19),
new Person("小明", 21))
.collect(Collectors.toList());
// 获取最大值
Optional<Person> optional = personList.stream()
.collect(Collectors.maxBy((o1, o2) -> o1.getAge() - o2.getAge()));
System.out.println("最大值: " + optional.get());
// 获取最小值
Optional<Person> optionalMin = personList.stream()
.collect(Collectors.minBy((o1, o2) -> o1.getAge() - o2.getAge()));
System.out.println("最小值: " + optionalMin.get());
// 求总和
Integer totalAge = personList.stream()
.collect(Collectors.summingInt(Person::getAge));
System.out.println("总和: " + totalAge);
// 平均值
Double avg = personList.stream()
.collect(Collectors.averagingInt(Person::getAge));
System.out.println("平均值: " + avg);
// 统计数量
Long count = personList.stream()
.collect(Collectors.counting());
System.out.println("总共: " + count);
// 以上方法聚合
IntSummaryStatistics summaryStatistics = personList.stream()
.collect(Collectors.summarizingInt(Person::getAge));
System.out.println("上面所有方法的聚合: " + summaryStatistics);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 对流中数据进行分组
- 当我们使用Stream流处理数据后,可以根据某个属性将数据分组
public class StreamCollectTest {
@Test
public void group(){
List<Person> personList = Stream.of(
new Person("张三", 18),
new Person("李四", 22),
new Person("王五", 18),
new Person("小红", 18),
new Person("小明", 21))
.collect(Collectors.toList());
// 通过年龄来进行分组
personList.stream()
.collect(Collectors.groupingBy(Person::getAge))
// 分组结果为键值对
.forEach((key, value) -> System.out.println(key + "::" + value));
// 将年龄大于19的分为一组, 小于19分为一组
personList.stream()
.collect(Collectors.groupingBy(s -> {
if(s.getAge() > 19){
return ">=19";
}else{
return "<19";
}
}))
// 分组结果为键值对, 键为groupingBy返回的数据
.forEach((k, v) -> System.out.println(k + "::" + v));
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 对流中数据进行多级分组
- 还可以对数据进行多级分组:
public class StreamCollectTest {
@Test
public void multiGroup(){
List<Person> personList = Stream.of(
new Person("张三丰", 18),
new Person("迪丽热巴", 22),
new Person("古力娜扎", 18),
new Person("迪迦奥特曼", 18),
new Person("宇宙无敌法外狂徒张三", 21))
.collect(Collectors.toList());
// 先根据年龄分组, 每组中再根据名字的长度分组
personList.stream()
.collect(
// 根据年龄分组
Collectors.groupingBy(p -> {
if(p.getAge() > 19){
return "大于19";
}else{
return "小于等于19";
}
},
// 根据名字长度分组
Collectors.groupingBy(p -> {
if(p.getName().length() > 4){
return "较长的名字";
}else{
return "较短的名字";
}
}))
)
// 结果的类型为: Map<String, Map<String, Person>>
.forEach((oneK, oneV) -> {
System.out.println("年龄" + oneK);
oneV.forEach((twoK, twoV) -> {
System.out.println("\t" + twoK + "::" + twoV);
});
});
/*
result -> {
年龄小于等于19
较长的名字::[Person{name='迪迦奥特曼', age=18}]
较短的名字::[Person{name='张三丰', age=18}, Person{name='古力娜扎', age=18}]
年龄大于19
较长的名字::[Person{name='宇宙无敌法外狂徒张三', age=21}]
较短的名字::[Person{name='迪丽热巴', age=22}]
}
*/
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 对流中数据进行分区
Collectors.partitioningBy会根据值是否为true,把集合分割为两个列表,一个true列表,一个false列表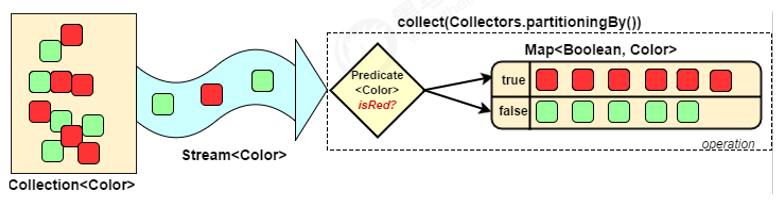
public class StreamCollectTest {
@Test
public void partition(){
List<Person> personList = Stream.of(
new Person("张三", 18),
new Person("李四", 22),
new Person("王五", 18),
new Person("小红", 18),
new Person("小明", 21))
.collect(Collectors.toList());
personList.stream()
// 将结果分为, true和false两个分区
.collect(Collectors.partitioningBy(p -> p.getAge() > 19))
.forEach((k, v) -> System.out.println(k + "::" + v));
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 对流中数据进行拼接
Collectors.joining会根据指定的连接符,将所有元素连接成一个字符串
public class StreamCollectTest {
@Test
public void join(){
List<Person> personList = Stream.of(
new Person("张三", 18),
new Person("李四", 22),
new Person("王五", 18),
new Person("小红", 18),
new Person("小明", 21))
.collect(Collectors.toList());
// 根据一个字符拼接
String names = personList.stream()
.map(Person::getName)
.collect(Collectors.joining("-"));
System.out.println(names);
// 根据三个字符拼接
names = personList.stream()
.map(Person::getName)
// 参数说明: 分隔符, 前缀, 后缀
.collect(Collectors.joining(",", "{", "}"));
System.out.println(names);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25